Keine Ahnung wer auf die Idee gekommen ist das nicht als Default zu haben aber wenn man micro in einer SSH Session verwendet funktionieren Copy/Paste innerhalb vom Dokument nicht so wie man das erwarten würde – seltsame Dinge mit der Maus gehen aber Strg+C/V erzeugt irgendeinen seltsamen Haufen aus irgendwelchen Clipboards.
Liveartikel mit vermutlich Updates – mal begonnen um nicht wieder Dinge zu vergessen für etwaige Diskussionen.
Was ist gut?
Die Idee. Selbstredend. Niemand will alleine von den Googles und Microsofts dieser Welt abhängig sein.
Die Auswahl der Komponenten.
Die technische Umsetzung von Rollout und Update.
Das „Company in a box“ Feeling. Und das mit wenigen Schritten live (wenn man mal weiß wie 😀 ).
Viel Standardinfrastruktur die viele vielleicht schon live haben (Kubernetes, Redis, Postgres, etc.).
Was ist weniger gut? (unsortiert)
Verzahnung
Wie bei den guten Sachen geschrieben sind ein paar Applikationen miteinander verbunden aber bei weitem nicht in allen Situationen die mir auf Anhieb eingefallen wären.
Warum Nextcloud nur für Dateien eingefügt worden ist erschließt sich mir nicht auf Anhieb wenn Open-XChange auch ähnliche Features hat (ohne die jemals gesehen zu haben – kann auch mit den eingebauten Offices der zwei Produkte zu tun haben).
Generell frage ich mich wieso Nextcloud UND Open-Xchange weil OX ja auch ein Drive hat aber wird schon seinen Grund haben. Dann aber auch bitte mehr von Nextcloud.
2FA
nur mit App was gut aber zuwenig ist, WebAuthn notwendig
immer enforced, man hat sich an conditional Access gewöhnt und ist nicht bereit im corporate LAN 2FA zu machen
Identity Management (Nubus von Univention)
nur das absolute Minimum vorhanden
ohne Zusätze nicht Enterprisetauglich (Plugins für vorhandenes Identity Management, Tools für 1st/2nd Level Support, Polices (für alle Produkte im Verbund) etc.)
So Kleinigkeiten wie dass ein OpenProject Admin nur wirksam wird wenn man ihn setzt bevor man OpenProject das erste mal benutzt mit dem betroffenen User werden hoffentlich gefixed und sind kein inheräntes Problem – zeigen aber den Sand im Getriebe.
wieder von einer Firma abhängig
Enterprise Edition
wieder proprietäre Extensions drinnen – nicht wie hier beschrieben die gleichen Inhalte, Unterschiede hier
OpenProject in der Community Edition sinnlos (ohne den Corporate Plan der EE)
OX/Dovecot Pro kann ich (noch) nicht bewerten
Community Edition kaum produktiv betreibbar (fairerweise wird, wenn auch inkonsistent, darauf hingewiesen)
Wieder License Keys. Wir wissen alle dass Lizenzen die dritte Geißel der EDV sind (Drucker und Zertifikate sind die anderen zwei falls sich jemand gefragt hat).
Die Releasegeschwindigkeit der Tools ist höher als die des Projekts – verständlich aber sollte irgendwann wieder annähernd gleichauf liegen.
Betrieb
Aktuell viele Updates – die alle Potenzial haben Dinge zu brechen. Wird sich naturgemäß ändern aber genauso gefährlich wie die monatlichen Updates bei M365 beispielsweise. Aber das Tempo muss man gehen und die auftretenden Disasterfälle behandeln können.
Für Produktion wird davon ausgegangen dass man viele Komponenten quasi im Bauchladen enterprisetauglich schon zur Verfügung hat (Redis, Postgres, S3, etc.) – völlig valider Ansatz aber muss einem klar sein – wenn mans selber machen will.
Dadurch dass viele Produkte zusammengewürfelt wurden bzw. vorausgesetzt werden muss man auch für alle Produkte Spezialisten haben die sich zu Themen des Betriebs (Verwaltung, Monitoring, Support, Backup/Restore, etc.) Gedanken machen – wenn mans selber machen will.
Kosten
Ich finde keine Kosten pro User/Monat für Enterprise Edition sowohl on prem als auch als SaaS. Wenn ich mir anschaue was alleine OpenProject so nimmt für seine Enterprise Features schwant mir nix Gutes. Und Univention will verständlicherweise für Nubus vermutlich auch Geld sehen.
SaaS
Schon valide weil wer hat schon die notwendige Expertise und Hardware vorrätig – aber gemäß Ausschreibungsgewinner liefert man sich dann halt der Schwarz IT als Betreiber und wer weiß wem als Ansprechpartner aus (für DE). Aber einen Gott muss man halt anbeten vermutlich (wenn mans nicht selbst machen kann oder will).
Theming
Schon weit fortgeschritten aber an der einen oder anderen Stelle zwickts noch. Vielleicht in der Enterprise Edition besser.
Zusammenfassung
Äußerst cooler Ansatz mit funktionierendem ersten Wurf samt jeder Menge Raum für Verbesserungen aber mit doch hohem Basisaufwand für Selbstbetreiber bzw. halt SaaS-Selbstauslieferung, dann halt immerhin in europäisch.
Die Minimum Requirements sind tatsächlich einzuhalten – ich bin mit 10 Cores gescheitert weil er dann einen Pod nicht schedulen konnte. Vielleicht Zufall/Pech aber mit 12 hatte ich konsistent keine Probleme – siehe Update 2026-01-02 32 GB RAM sind machbar – am Ende sind ca. 20 GB in use – aber am Weg gehen 40 GB für Cache drauf – pendelt sich dann auch weit nach unten (10 GB) ein aber langsamer wirds damit sicher nicht.
Mit irgendeiner OpenProject Version ist sticky bit Support beim Kubernetes Storage Provider Voraussetzung geworden, das Deployment bleibt mit dem Default local-path Provider dann hängen. (Fußnote 2 auf https://docs.opendesk.eu/operations/requirements/)
Helm diff Plugin hat bei mir auch nur mit 3.12.4 funktioniert.
Helmfile hat bei mir auch nur mit 1.2.2 funktioniert.
Weil wir anderes Storage brauchen auf Longhorn gewechselt, das hat aber Single Node auch spezielle Herausforderungen weil in der Defaultinstallation das Setup nach einem Reboot vom Host sonst kaputt ist.
Vorgehen:
Das longhorn.yaml aus dem Setup nur runterladen aber nicht gleich applyen.
Das Deployment für longhorn-driver-deployer um folgende Environmentvariablen erweitern damit nur jeweils ein Pod für Attacher/Provisioner/Resizer/Snapshotter erzeugt wird: - name: CSI_ATTACHER_REPLICA_COUNT value: "1" - name: CSI_PROVISIONER_REPLICA_COUNT value: "1" - name: CSI_RESIZER_REPLICA_COUNT value: "1" - name: CSI_SNAPSHOTTER_REPLICA_COUNT value: "1"
ConfigMap longhorn-default-setting bei data/default-setting.yaml um folgende Settings erweitern (default-data-path natürlich optional, ich hatte zweite Disk eingehängt): default-data-path: "/longhorn" default-replica-count: 1 node-drain-policy: "always-allow" auto-salvage: true
ConfigMap longhorn-storageClass den parameter „numberOfReplicas“ von „3“ auf „1“ ändern numberOfReplicas: "1"
Im Deployment longhorn-ui die Replicas von 2 auf 1 stellen replicas: 1
Im values.yaml.gotmpl fürs openDesk deployment (Punkt 3.2 in der Anleitung „Customizing the environment“) Storage umstellen: persistence: storageClassNames: RWO: "longhorn"
Da die Wahrscheinlichkeit dass alle Longhorn Volumes nach einem Reboot korrupt sind bei annähernd 100% liegt sollte man vor so einem Reboot alle Deployments und Statefulsets im openDesk Namespace auf 0 setzen und danach wieder zurück auf 1.
( Und ja das ist sicher gegen 2000 Kubernetes Gesetze und der Fahndungszettel für mich hängt schon überall aber für mich funktionierts 😀 )
Updates:
2026-01-02: die CPU Problematik ist heute virulent geworden weil die Komponente openxchangeCoreMW CPU requests von 1 macht (anstatt vermutlich 0.1 wie die meisten anderen auch), daher in die values.yaml.gotmpl fürs Deployment eingefügt: resources: openxchangeCoreMW: requests: cpu: 0.1
mit sudo dnf install ./freerdp-3.20.0-1.fc42.x86_64.rpm ./freerdp-libs-3.20.0-1.fc42.x86_64.rpm ./libwinpr-3.20.0-1.fc42.x86_64.rpm in einem Rutsch installieren
Sicherstellen dass CUPS läuft: sudo systemctl start cups
Drucker verbinden
sudo system-config-printer
Add / Network Printer / Find Network Printer / IP bei Host angeben und Find
Warten bis er Amok läuft und 2000 Einträge mit der IP-Adresse in der Liste baut – aber auch eben einen Eintrag „Epson WF-7610 (IP-Adresse)„
Diesen Eintrag auswählen (Host wird mit Port 515 vorbefüllt und Queue „PASSTHRU“) und „Probe“ klicken, „Searching for drivers“ sollte aufgehen und verschwinden.
Der Odyssey G9 (ein S49FG910EU bei mir) hat 5120×1440 und kann 144 Hz.
Mein Mini PC (Ninkear K7 mit einer Ryzen 7430U) hat nur HDMI.
Damit 5120×1440 in höheren Refreshraten läuft braucht man HDMI 2.1.
AMD darf unter Linux aus irgendeinem dummen Grund nicht HDMI 2.1 machen.
Ergo: Linux sieht als höchstes der Gefühle 3840×1080@120 oder so was natürlich nicht Sinn der Sache ist und auch noch Kacke aussieht.
Lösung für 144 Hz: Display Port.
Da ich aber keinen neuen Mini PC kaufen will funktioniert folgender 5120×1440@60 Workaround (da ich jetzt auf KDE/Arch fahre und demnächst auf QubesOS – beide mit X11- umsteige):
Update: Ein Adapter von USB-C auf Display Port hat das Problem ohne neuen Mini PC gelöst 😀 (Qubes OS/X11 springt instant auf die native Auflösung in 120 Hz, 144 ist aber auch in der Liste)
Scheinbar hat Apple ab iOS 16.2 beschlossen nur mehr vCard 3.0 oder höher zu unterstützen. Outlook, selbst in der neuesten M365 Version exportiert aber 2.1 – Mobile Safari spuckt dann lapidar „Safari cannot download this file“ aus.
Falle 2:
Also, man will ja auch was lernen, hab ich mit pythonvCard4 eine 4.0 vCard erzeugt. Mit Bild natürlich. Konnte iOS auch auf Anhieb öffnen, Android auch aber dort wurde ein Kontakt erzeugt der den Base64 Wert vom Bild im Namen hatte.
Aus irgendeinem Grund macht Android das wenn die Namensfelder („FN“ und „N“) vorm PHOTO Feld stehen. Also zuerst PHOTO dann FN/N im vCard File.
Falle 3:
Weiß nimmer genau wer mit was umgehen kann aber auf alle Fälle hab ich jetzt das PHOTO zweimal drin, einmal mit
Falls ich oder irgendwer es jemals wieder wo braucht 😀 Single host. Kein TLS. Ohne Schusswaffe. Nur um es mal gesehen zu haben.
Minio AGPL3 runterladen und installieren (erzeugt systemd Service „minio„, User und Gruppe „minio-user“ und Config auf /etc/default/minio) – ist seltsam weil offenbar je nach Download URL andere Lizenz im Executable eingebacken ist:
## Volume to be used for MinIO server.
MINIO_VOLUMES="/data/minio"
## Use if you want to run MinIO on a custom port.
MINIO_OPTS="--address :9198 --console-address :9199"
## Root user for the server.
MINIO_ROOT_USER=whatever1
## Root secret for the server.
MINIO_ROOT_PASSWORD=whatever2
## set this for MinIO to reload entries with 'mc admin service restart'
MINIO_CONFIG_ENV_FILE=/etc/default/minio
Der Datenpfad muss dem minio User gehören:
sudo chmod -R minio-user:minio-user /data/minio
Minio starten und systemd journal checken was abgeht:
Im Webinterface (Port 9199 gemäß obiger Config) kann man nicht viel machen außer Buckets verwalten (anlegen/löschen), daher brauchen wir MC, das CLI:
wget https://dl.min.io/client/mc/release/linux-amd64/mc
chmod +x mc
sudo cp mc /usr/local/bin/
mc braucht auch ein config file welches beim ersten Aufruf mit Defaultwerten befüllt wird (die nicht funktionieren oder wir erzeugen selbst eines – die Keys sind User/PW von /etc/default/minio) – die ist unter ~/.mc/config.json zu speichern:
Wir erzeugen ein Bucket und setzen die Region des Servers (+Restart desselben):
mc mb local/longhornbackup
mc admin config set local region name=myregion
mc admin service restart local
Dann brauchen wir noch eine Zugriffspolicy (Einschränkung auf unseren Bucket den wir soeben erzeugt haben) die wir dann unserem Backupuser zuordnen (minio-longhornbackup-policy.json):
Zuletzt legen wir einen User samt Access Key für Longhorn Config an und attachen die Policy (das local ist der Alias der Konfiguration aus der ~/.mc/config.json, das Kennwort ist irrelevant weil wir eh mit accesskey zugreifen):
mc admin user add local longhorn irgendeinkennwort
mc admin accesskey create local longhorn
mc admin policy create local longhornbackup ./minio-longhornbackup-policy.json
mc admin policy attach local longhornbackup --user longhorn
Mit den Werten die die accesskey Erzeugung unter „Access Key“ und „Secret Key“ ausgespuckt hat erzeugen wir ein Kubernetes Secret im longhorn-system Namespace (minio-secret hier, beim AWS_ENDPOINTS Wert den Servernamen auf dem Minio läuft plus den Port für API aus /etc/default/minio dort verwenden):
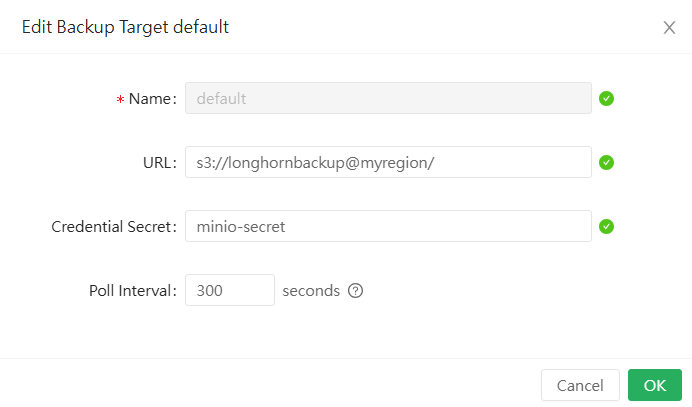
Zuletzt tragen wir das Backup Target im Longhorn Web UI noch unter Setting/Backup Target ein wobei der Teil vor dem @ der Name des Bucket ist und das hinterm @ die Region die wir gesetzt haben:
Problem: VPS mit rootless Podman Container die (völlig überraschend) Daten erzeugen die man (auch völlig überraschend) sichern will – aber nicht beim Hoster wegen Kosten und 3-2-1 Regel (wenn wir uns mal das 3 und 2 wegdenken).
Subproblem: Wegen UID Mapping haben die Daten die Container erzeugt einen Owner mit einer gemappten UID und somit kann der (unberechtigte) User der die Podman Container betreibt nicht auf die Daten zugreifen.
Lösung: Daten mit root und rclone als TAR (wegen Erhalt UIDs) nach OneDrive sichern und mit rclone alte Files löschen lassen.
rclone installieren
rclone config
als Name „onedrive“ angeben
type of storage „Microsoft OneDrive“ auswählen (bei mir 31)
client_id, client_secret überspringen
Region „Microsoft Cloud Global“
Advanced config: no
Auto Config: no
Auf Rechner mit Browser rclone authorize "onedrive" --onedrive-auth-url https://login.microsoftonline.com/<tenant-guid>/oauth2/v2.0/authorize --onedrive-token-url https://login.microsoftonline.com/<tenant-guid>/oauth2/v2.0/token
Output in config_token reinpasten
config_type=OneDrive Personal or Business (1 bei mir)
drive_id=das mit „Documents“ oder „Dokumente“ (1 bei mir)
Drive OK bestätigen
~/.config/rclone/rclone.conf auf /root/.config/rclone/rclone.conf kopieren
Backupscript erstellen (s.u.) ggf. --min-age anpassen wenn man Backups länger als 3 Monate aufheben will. Script geht davon aus dass User mit dem Container laufen podman heißt (-M podman@ im systemctl Call) und der Container mycontainer als Service podman-mycontainer im Ordner /path/to/mycontainerparent läuft und auf /targetfolder/on/onedrive gesichert werden soll.
Aufruf in System crontab einfügen (muss als root laufen weil die Dateien die im Container erzeugt werden ja UID-mapped sind und für normale User nicht zugreifbar sind).