Seit Version 3.25 kann FreeRDP das was MSTSC schon einige Jahre mittlerweile kann: WebAuthn in einen virtual RDP channel in die Sitzung redirecten.
Da Remmina eigentlich libfreerdp verwendet sollte es eigentlich auch dort gehen wenn man den entsprechenden dynamic virtual channel (rdpewa) aktiviert aber ich nehme an es gibt keine Möglichkeit dann PIN-Eingabe „abzufangen“, daher vorerst noch nicht möglich.
Damit ich nicht wieder 3 Stunden brauche um die Command Line zusammenzupfistern (paar Performanceparameter und spezielles Sizing für meinen Ultrawide im Qubes OS Fullscreen (mit Fensterbar) – ansonsten einfach /f für Fullscreen und vielleicht /dynamic resolution verwenden):
Bonusinformation: Wenn man in der Session dann im Firefox Webauthn machen will passiert nix, setzt man via about:config den Parameter security.webauthn.always_allow_direct_attestation auf true funktionierts auch dort. Chromium basierte (Chrome, Edge, Vivaldi getestet) Browser haben da kein Problem.
Nach einem Crash des OS und Hard-Off kann nur mehr dom0 booten, alle anderen Qubes liefern „Start failed: Logical Volume „vmname-private-snap“ already exists in volume soundso“ beim Start.
Lösung ist hier beschrieben (Transaction ID in der Config im logical volume für die VM Disken passen nicht mit der Realität zusammen), fasse dennoch zusammen falls der Eintrag irgendwann verloren geht bzw. findet man genau das dann eh wieder nicht wenn man es sucht 😀
#check ob wir vom transaction problem sprechen - sollte entsprechende Fehlermeldung bring
sudo lvconvert --repair qubes_dom0/vm-pool
# config sichern, user durch dom0 username ersetzen
sudo vgcfgbackup qubes_dom0 -f /home/user/VG_backup
# config editieren, transaction ID suchen und durch die andere in der Fehlermeldung ersetzen
sudo micro /home/user/VG_backup
# config restoren
sudo vgcfgrestore qubes_dom0 -f /home/user/VG_backup --force
# LV live bringen
sudo lvchange -ay qubes_dom0
# falls noch fehlermeldungen mit logical volumes (snap etc.) kommen diese löschen
sudo lvremove qubes_dom0/vmname-private-snap
UPDATE: Weiß ja nicht was bei Microsoft so aus der Wand dampft aber die gespeicherten PublisherPermissions verhindern scheinbar NICHT den Warndialog. Die Aktion die hier weiter unten beschrieben wird ist also eher akademischer Natur.
UPDATE 2: Specify SHA1 thumbprints of certificates representing trusted .rdp publishers in User oder Computer Configuration\ Administrative Templates\ Windows Components\ Remote Desktop Services\ Remote Desktop Connection Client ist unser Freund.
Microsoft hat mit den April Updates versucht den RDP Client sicherer zu machen, was ein klein wenig nach hinten losgegangen ist weil mit den erzwungenen „Fehlermeldungen“ kann niemand was anfangen.
Wenn man dann so wie ich einen RDP Wrapper hat der mit dynamisch erzeugten (und signierten) RDP Files im Enterpriseumfeld (=keine Dialoge erwünscht) arbeitet ist das mehr als ärgerlich.
Man kann jetzt die im Internet seit heute kursierende Policy anwenden die das Verhalten ausschaltet (und damit auch den eigentlich Zweck der Aktion töten) oder wie folgt vorgehen:
Wir brauchen SHA256 Thumbprint des Zertifikats welches die RDP Files signiert. Natürlich dynamisch und nicht statisch. Kann man mit openssl lösen (openssl.exe x509 -noout -fingerprint -sha256 -inform pem -in meinzert.pem) aber wir wollens ja programmatisch machen (davon ausgehend dass das Zertifikat in oCert aus dem Store der Wahl gelesen wurde):
using System.Security.Cryptography; // für SHA256Managed
using System.Security.Cryptography.X509Certificates; // fürs Cert/RawData
using System.Linq; // fürs Aggregate
string sSHA256Thumbprint = new
SHA256Managed().ComputeHash(oCert.RawData).Aggregate(String.Empty, (sHash, nByte) => sHash + nByte.ToString("x2"));
Mit Powershell gehts natürlich auch, hier das erstbeste Zertifikat im Maschinenstore:
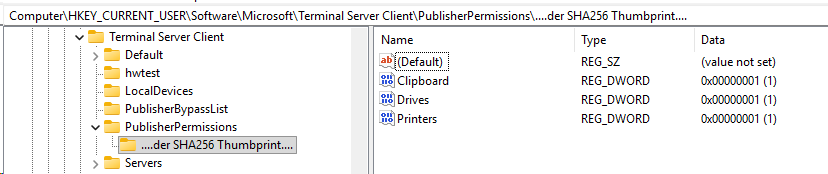
Diesen SHA256 Thumbprint (erweitert um ein „00“ hinten) legen wir als Key dann unter HKCU/Software/Microsoft/Terminal Server Client/PublisherPermissions an.
In diesem Key muss man dann für jedes Mapping welches man verwenden will einen Wert mit 1 (enabled) oder 0 (disabled) erzeugen, also beispielsweise: Drives, Printers, Clipboard, SmartCards.
Sieht dann beispielhaft so aus:
Um den „willst du überhaupt RDP Files zulassen“ Dialog zu unterdrücken kann man auch noch den Wert HKCU/Software/Microsoft/Terminal Server Client/RdpLaunchConsentAccepted erzeugen und auf 1 setzen.
das ganze sitzt auf einem Server der nur via Proxy ins Internet kommt (warum ist das wichtig? Next-Auth will Profil lesen und braucht dafür Internet, die verwendete http Library kann aber keinen Proxy)
das alles sitzt hinter einem NGINX der reverse Proxy für App oder Container mit der App spielt (warum ist das wichtig? Diverse Redirects die Next-Auth und Entra machen funktionieren nur mit bestimmten NGINX Proxy Settings)
Der Witz ist dass sich tatsächlich jemand gefunden hat der das Problem mit dem (forward) Proxy gelöst hat: https://next-auth.js.org/tutorials/corporate-proxy, muss so 2022 gewesen sein und wurde auch im Juni 2025 zuletzt aktualisert funktioniert so aber nicht (mehr) – mit next-auth 4.24.13 in meinem Projekt UND der Azure Teil hat im Original und in der Änderung massives Problem wenn ein Request schief geht, nämlich keinerlei Fehlerhandling, crashed einfach raus.
Das neue node_modules/next-auth/providers/azure-ad.js sieht also so aus:
Das neue node_modules/next-auth/core/lib/oauth/client.js entspricht fast dem aus dem Artikel, nur das HttpsProxyAgent muss man auf HttpsProxyAgent.HttpsProxyAgent beim instanzieren ändern:
"use strict";
Object.defineProperty(exports, "__esModule", {
value: true
});
exports.openidClient = openidClient;
var _openidClient = require("openid-client");
var HttpsProxyAgent = require("https-proxy-agent");
async function openidClient(options) {
const provider = options.provider;
// if (provider.httpOptions) _openidClient.custom.setHttpOptionsDefaults(provider.httpOptions);
// let issuer;
// NEU >
let httpOptions = {};
if (provider.httpOptions) httpOptions = { ...provider.httpOptions };
if (process.env.http_proxy) {
let agent = new HttpsProxyAgent.HttpsProxyAgent(process.env.http_proxy);
httpOptions.agent = agent;
}
// NEU <
_openidClient.custom.setHttpOptionsDefaults(httpOptions);
let issuer;
if (provider.wellKnown) {
issuer = await _openidClient.Issuer.discover(provider.wellKnown);
} else {
var _provider$authorizati, _provider$token, _provider$userinfo;
issuer = new _openidClient.Issuer({
issuer: provider.issuer,
authorization_endpoint: (_provider$authorizati = provider.authorization) === null || _provider$authorizati === void 0 ? void 0 : _provider$authorizati.url,
token_endpoint: (_provider$token = provider.token) === null || _provider$token === void 0 ? void 0 : _provider$token.url,
userinfo_endpoint: (_provider$userinfo = provider.userinfo) === null || _provider$userinfo === void 0 ? void 0 : _provider$userinfo.url,
jwks_uri: provider.jwks_endpoint
});
}
const client = new issuer.Client({
client_id: provider.clientId,
client_secret: provider.clientSecret,
redirect_uris: [provider.callbackUrl],
...provider.client
}, provider.jwks);
client[_openidClient.custom.clock_tolerance] = 10;
return client;
}
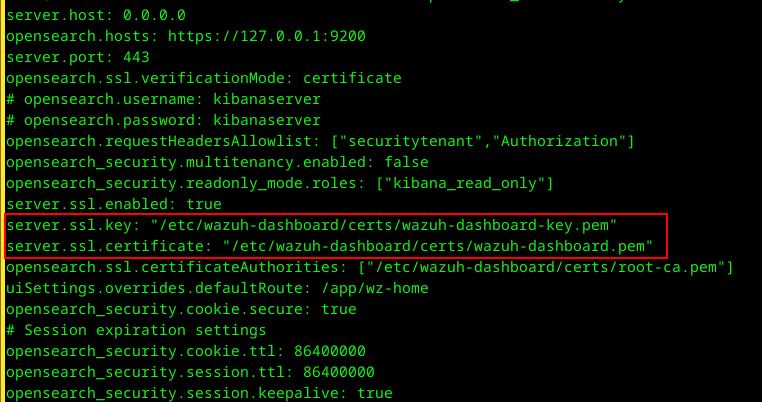
Es steht im Nachhinein gesehen eh klipp und klar in der Anleitung – nur server.ssl.key und server.ssl.certificate tauschen aber man ist es irgendwie so gewohnt und tauscht natürlich auch opensearch.ssl.certificateAuthorities aus was zum lt. Googlesuche beliebten „unable to verify first certificate“ führt weil das in Wahrheit das interne Zertifikat ist mit dem die Komponenten untereinander connecten….
Daher nur die Files hinter den beiden Parametern wechseln oder halt überschreiben:
Ob in server.ssl.certificate tatsächlich die ganze Chain enthalten sein muss weiß ich nicht wirklich – ich hab intern keine Intermediate CA und hab die Root CA nicht im PEM File.
Hier die OpenSearch Dokumentation – sollte einem eigentlich eh instant auffallen dass die einen Parameter mit „server“ beginnen und die anderen mit „opensearch“ – wär halt maximal fantastisch wenn das in getrennten Files landen würd?
Keine Ahnung wer auf die Idee gekommen ist das nicht als Default zu haben aber wenn man micro in einer SSH Session verwendet funktionieren Copy/Paste innerhalb vom Dokument nicht so wie man das erwarten würde – seltsame Dinge mit der Maus gehen aber Strg+C/V erzeugt irgendeinen seltsamen Haufen aus irgendwelchen Clipboards.
Liveartikel mit vermutlich Updates – mal begonnen um nicht wieder Dinge zu vergessen für etwaige Diskussionen.
Was ist gut?
Die Idee. Selbstredend. Niemand will alleine von den Googles und Microsofts dieser Welt abhängig sein.
Die Auswahl der Komponenten.
Die technische Umsetzung von Rollout und Update.
Das „Company in a box“ Feeling. Und das mit wenigen Schritten live (wenn man mal weiß wie 😀 ).
Viel Standardinfrastruktur die viele vielleicht schon live haben (Kubernetes, Redis, Postgres, etc.).
Was ist weniger gut? (unsortiert)
Verzahnung
Wie bei den guten Sachen geschrieben sind ein paar Applikationen miteinander verbunden aber bei weitem nicht in allen Situationen die mir auf Anhieb eingefallen wären.
Warum Nextcloud nur für Dateien eingefügt worden ist erschließt sich mir nicht auf Anhieb wenn Open-XChange auch ähnliche Features hat (ohne die jemals gesehen zu haben – kann auch mit den eingebauten Offices der zwei Produkte zu tun haben).
Generell frage ich mich wieso Nextcloud UND Open-Xchange weil OX ja auch ein Drive hat aber wird schon seinen Grund haben. Dann aber auch bitte mehr von Nextcloud.
2FA
nur mit App was gut aber zuwenig ist, WebAuthn notwendig
immer enforced, man hat sich an conditional Access gewöhnt und ist nicht bereit im corporate LAN 2FA zu machen
Identity Management (Nubus von Univention)
nur das absolute Minimum vorhanden
ohne Zusätze nicht Enterprisetauglich (Plugins für vorhandenes Identity Management, Tools für 1st/2nd Level Support, Polices (für alle Produkte im Verbund) etc.)
So Kleinigkeiten wie dass ein OpenProject Admin nur wirksam wird wenn man ihn setzt bevor man OpenProject das erste mal benutzt mit dem betroffenen User werden hoffentlich gefixed und sind kein inheräntes Problem – zeigen aber den Sand im Getriebe.
wieder von einer Firma abhängig
Enterprise Edition
wieder proprietäre Extensions drinnen – nicht wie hier beschrieben die gleichen Inhalte, Unterschiede hier
OpenProject in der Community Edition sinnlos (ohne den Corporate Plan der EE)
OX/Dovecot Pro kann ich (noch) nicht bewerten
Community Edition kaum produktiv betreibbar (fairerweise wird, wenn auch inkonsistent, darauf hingewiesen)
Wieder License Keys. Wir wissen alle dass Lizenzen die dritte Geißel der EDV sind (Drucker und Zertifikate sind die anderen zwei falls sich jemand gefragt hat).
Die Releasegeschwindigkeit der Tools ist höher als die des Projekts – verständlich aber sollte irgendwann wieder annähernd gleichauf liegen.
Betrieb
Aktuell viele Updates – die alle Potenzial haben Dinge zu brechen. Wird sich naturgemäß ändern aber genauso gefährlich wie die monatlichen Updates bei M365 beispielsweise. Aber das Tempo muss man gehen und die auftretenden Disasterfälle behandeln können.
Für Produktion wird davon ausgegangen dass man viele Komponenten quasi im Bauchladen enterprisetauglich schon zur Verfügung hat (Redis, Postgres, S3, etc.) – völlig valider Ansatz aber muss einem klar sein – wenn mans selber machen will.
Dadurch dass viele Produkte zusammengewürfelt wurden bzw. vorausgesetzt werden muss man auch für alle Produkte Spezialisten haben die sich zu Themen des Betriebs (Verwaltung, Monitoring, Support, Backup/Restore, etc.) Gedanken machen – wenn mans selber machen will.
Kosten
Ich finde keine Kosten pro User/Monat für Enterprise Edition sowohl on prem als auch als SaaS. Wenn ich mir anschaue was alleine OpenProject so nimmt für seine Enterprise Features schwant mir nix Gutes. Und Univention will verständlicherweise für Nubus vermutlich auch Geld sehen.
SaaS
Schon valide weil wer hat schon die notwendige Expertise und Hardware vorrätig – aber gemäß Ausschreibungsgewinner liefert man sich dann halt der Schwarz IT als Betreiber und wer weiß wem als Ansprechpartner aus (für DE). Aber einen Gott muss man halt anbeten vermutlich (wenn mans nicht selbst machen kann oder will).
Theming
Schon weit fortgeschritten aber an der einen oder anderen Stelle zwickts noch. Vielleicht in der Enterprise Edition besser.
Zusammenfassung
Äußerst cooler Ansatz mit funktionierendem ersten Wurf samt jeder Menge Raum für Verbesserungen aber mit doch hohem Basisaufwand für Selbstbetreiber bzw. halt SaaS-Selbstauslieferung, dann halt immerhin in europäisch.
Die Minimum Requirements sind tatsächlich einzuhalten – ich bin mit 10 Cores gescheitert weil er dann einen Pod nicht schedulen konnte. Vielleicht Zufall/Pech aber mit 12 hatte ich konsistent keine Probleme – siehe Update 2026-01-02 32 GB RAM sind machbar – am Ende sind ca. 20 GB in use – aber am Weg gehen 40 GB für Cache drauf – pendelt sich dann auch weit nach unten (10 GB) ein aber langsamer wirds damit sicher nicht.
Mit irgendeiner OpenProject Version ist sticky bit Support beim Kubernetes Storage Provider Voraussetzung geworden, das Deployment bleibt mit dem Default local-path Provider dann hängen. (Fußnote 2 auf https://docs.opendesk.eu/operations/requirements/)
Helm diff Plugin hat bei mir auch nur mit 3.12.4 funktioniert.
Helmfile hat bei mir auch nur mit 1.2.2 funktioniert.
Weil wir anderes Storage brauchen auf Longhorn gewechselt, das hat aber Single Node auch spezielle Herausforderungen weil in der Defaultinstallation das Setup nach einem Reboot vom Host sonst kaputt ist.
Vorgehen:
Das longhorn.yaml aus dem Setup nur runterladen aber nicht gleich applyen.
Das Deployment für longhorn-driver-deployer um folgende Environmentvariablen erweitern damit nur jeweils ein Pod für Attacher/Provisioner/Resizer/Snapshotter erzeugt wird: - name: CSI_ATTACHER_REPLICA_COUNT value: "1" - name: CSI_PROVISIONER_REPLICA_COUNT value: "1" - name: CSI_RESIZER_REPLICA_COUNT value: "1" - name: CSI_SNAPSHOTTER_REPLICA_COUNT value: "1"
ConfigMap longhorn-default-setting bei data/default-setting.yaml um folgende Settings erweitern (default-data-path natürlich optional, ich hatte zweite Disk eingehängt): default-data-path: "/longhorn" default-replica-count: 1 node-drain-policy: "always-allow" auto-salvage: true
ConfigMap longhorn-storageClass den parameter „numberOfReplicas“ von „3“ auf „1“ ändern numberOfReplicas: "1"
Im Deployment longhorn-ui die Replicas von 2 auf 1 stellen replicas: 1
Im values.yaml.gotmpl fürs openDesk deployment (Punkt 3.2 in der Anleitung „Customizing the environment“) Storage umstellen: persistence: storageClassNames: RWO: "longhorn"
Da die Wahrscheinlichkeit dass alle Longhorn Volumes nach einem Reboot korrupt sind bei annähernd 100% liegt sollte man vor so einem Reboot alle Deployments und Statefulsets im openDesk Namespace auf 0 setzen und danach wieder zurück auf 1.
( Und ja das ist sicher gegen 2000 Kubernetes Gesetze und der Fahndungszettel für mich hängt schon überall aber für mich funktionierts 😀 )
Updates:
2026-01-02: die CPU Problematik ist heute virulent geworden weil die Komponente openxchangeCoreMW CPU requests von 1 macht (anstatt vermutlich 0.1 wie die meisten anderen auch), daher in die values.yaml.gotmpl fürs Deployment eingefügt: resources: openxchangeCoreMW: requests: cpu: 0.1
mit sudo dnf install ./freerdp-3.20.0-1.fc42.x86_64.rpm ./freerdp-libs-3.20.0-1.fc42.x86_64.rpm ./libwinpr-3.20.0-1.fc42.x86_64.rpm in einem Rutsch installieren
Sicherstellen dass CUPS läuft: sudo systemctl start cups
Drucker verbinden
sudo system-config-printer
Add / Network Printer / Find Network Printer / IP bei Host angeben und Find
Warten bis er Amok läuft und 2000 Einträge mit der IP-Adresse in der Liste baut – aber auch eben einen Eintrag „Epson WF-7610 (IP-Adresse)„
Diesen Eintrag auswählen (Host wird mit Port 515 vorbefüllt und Queue „PASSTHRU“) und „Probe“ klicken, „Searching for drivers“ sollte aufgehen und verschwinden.